News
- 2nd Workshop on What is Next in Multimodal Foundation Models?
- MMFM-Challenge
Papers
|
|
|
LeGrad: An Explainability Method for Vision Transformers via Feature Formation Sensitivity
Walid Bousselham, Angie Boggust, Sofian Chaybouti, Hendrik Strobelt, Hilde Kuehne ICCV 2025
|
|
|
|
Teaching VLMs to Localize Specific Objects from In-context Examples (IPLoc)
Sivan Doveh, Nimrod Shabtay, Wei Lin, Eli Schwartz, Hilde Kuehne, Raja Giryes, Rogerio Feris, Leonid Karlinsky, James Glass, Assaf Arbelle, Shimon Ullman, M. Jehanzeb Mirza ICCV 2025 |
|
|
|
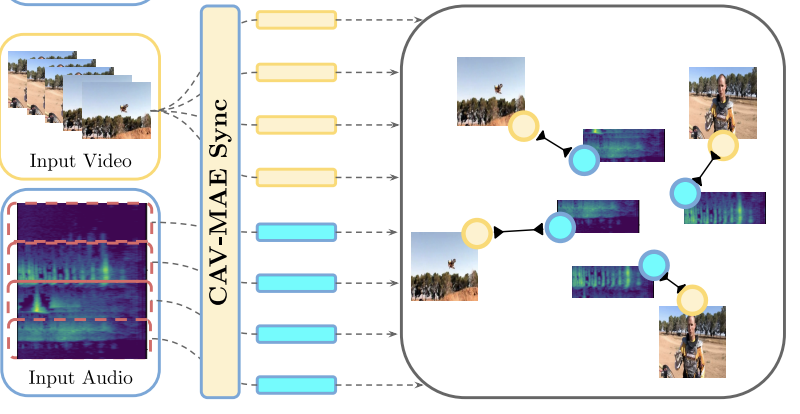
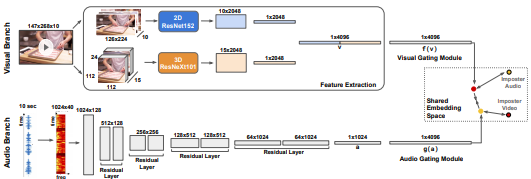
CAV-MAE Sync: Improving Contrastive Audio-Visual Mask Autoencoders via Fine-Grained Alignment
Edson Araujo, Andrew Rouditchenko, Yuan Gong, Saurabhchand Bhati, Samuel Thomas, Brian Kingsbury, Leonid Karlinsky, Rogerio Feris, James R. Glass, Hilde Kuehne CVPR 2025 |
|
|
|
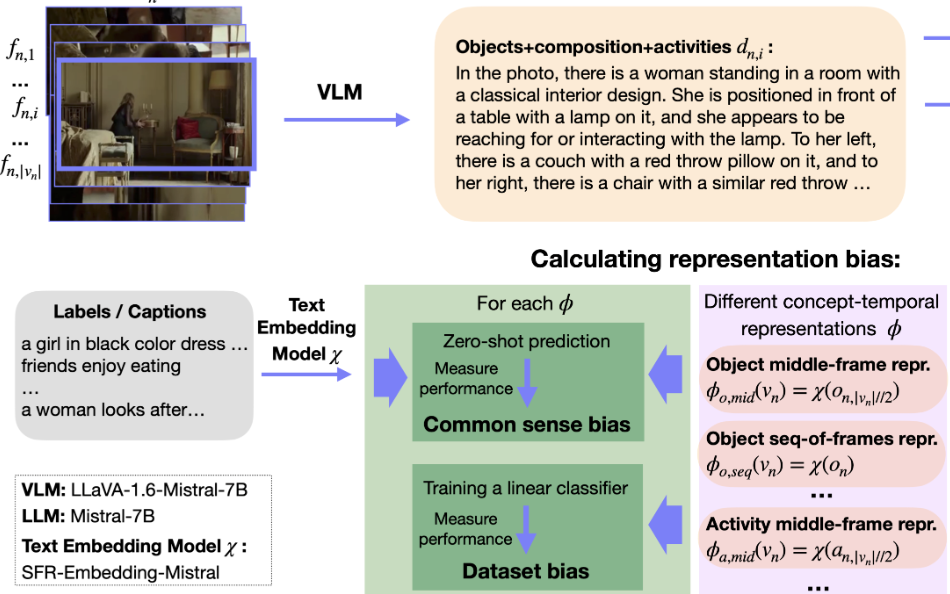
Unbiasing through Textual Descriptions: Mitigating Representation Bias in Video Benchmarks
Nina Shvetsova, Arsha Nagrani, Bernt Schiele, Hilde Kuehne, Christian Rupprecht CVPR 2025 |
|
|
|
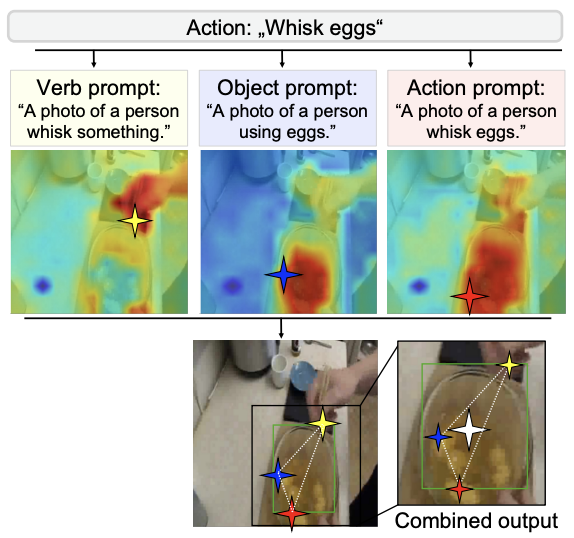
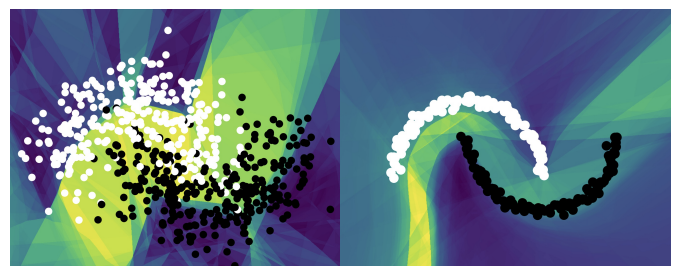
VideoGEM: Training-free Action Grounding in Videos
Felix Vogel, Walid Bousselham, Anna Kukleva, Nina Shvetsova, Hilde Kuehne CVPR 2025 |
|
|
|
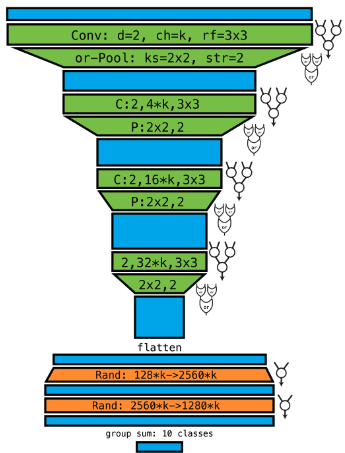
Convolutional Differentiable Logic Gate Networks
Felix Petersen, Hilde Kuehne, Christian Borgelt, Julian Welzel, Stefano Ermon NeurIPS 2024 (oral)
|
|
|
|
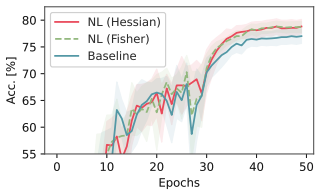
Fishers and Hessians of Continuous Relaxations
Felix Petersen, Christian Borgelt, Tobias Sutter, Hilde Kuehne, Oliver Deussen, Stefano Ermon NeurIPS 2024
|
|
|
|
ConMe: Rethinking Evaluation of Compositional Reasoning for Modern VLMs
Irene Huang, Wei Lin, Muhammad Mirza, Jacob Hansen, Sivan Doveh, Victor Butoi, Roei Herzig, Assaf Arbelle, Hilde Kuehne, Trevor Darrell, Chuang Gan, Aude Oliva, Rogerio Feris, Leonid Karlinsky NeurIPS D&B 2024 |
|
|
|
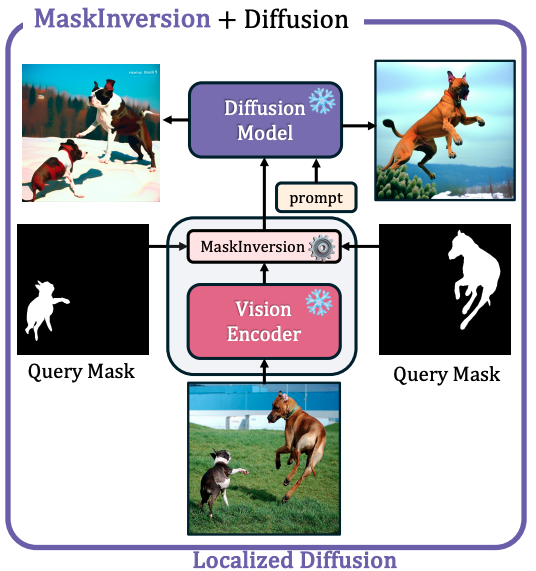
MaskInversion: Localized Embeddings via Optimization of Explainability Maps
Walid Bousselham, Sofian Chaybouti, Christian Rupprecht, Vittorio Ferrari, Hilde Kuehne arxiv 2024 |
|
|
|
HowToCaption: Prompting LLMs to Transform Video Annotations at Scale
Nina Shvetsova, Anna Kukleva, Xudong Hong, Christian Rupprecht, Bernt Schiele, Hilde Kuehne ECCV 2024 |
|
|
|
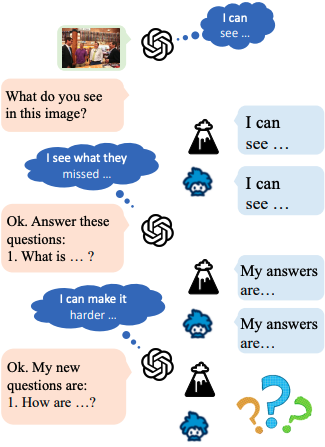
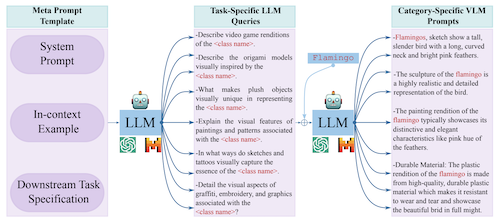
Meta-Prompting for Automating Zero-shot Visual Recognition with LLMs
M. Jehanzeb Mirza, Leonid Karlinsky, Wei Lin, Sivan Doveh, Jakub Micorek, Mateusz Kozinski, Hilde Kuhene, Horst Possegger ECCV 2024 |
|
|
|
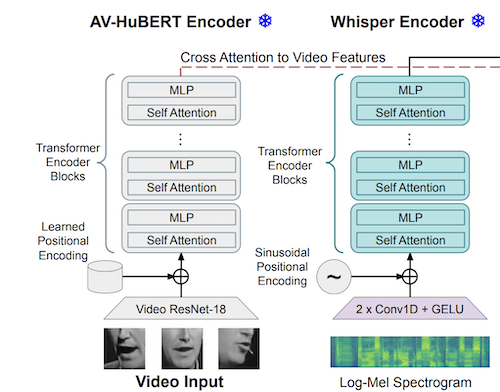
Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation
Andrew Rouditchenko, Yuan Gong, Samuel Thomas, Leonid Karlinsky, Hilde Kuehne, Rogerio Feris, James Glass Interspeech 2024
|
|
|
|
Grounding Everything: Emerging Localization Properties in Vision-Language Transformers
Walid Bousselham, Felix Petersen, Vittorio Ferrari, Hilde Kuehne CVPR 2024
|
|
|
|
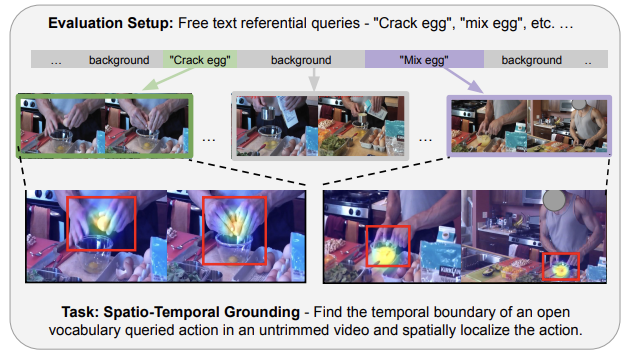
What, when, and where? - Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions
Brian Chen, Nina Shvetsova, Andrew Rouditchenko, Daniel Kondermann, Samuel Thomas, Shih-Fu Chang, Rogerio Feris, James Glass, Hilde Kuehne CVPR 2024 |
|
|
|
Uncertainty Quantification via Stable Distribution Propagation
Felix Petersen, Aashwin Mishra, Hilde Kuehne, Christian Borgelt, Oliver Deussen, Mikhail Yurochkin ICLR 2024 |
|
|
|
What a MESS: Multi-Domain Evaluation of Zero-Shot Semantic Segmentation
Benedikt Blumenstiel, Johannes Jakubik, Hilde Kühne, Michael Voessing NeurIPS D&B 2023 |
|
|
|
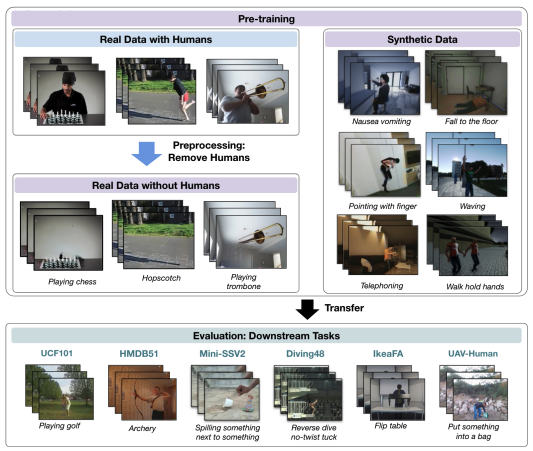
Learning Human Action Recognition Representations Without Real Humans
Howard Zhong, Samarth Mishra, Donghyun Kim, SouYoung Jin, Rameswar Panda, Hilde Kuehne, Leonid Karlinsky, Venkatesh Saligrama, Aude Oliva, Rogerio Feris NeurIPS D&B 2023 |
|
|
|
In-Style: Unsupervised Text-Video Retrieval with Style Preservation
Nina Shvetsova, Anna Kukleva, Bernt Schiele, Hilde Kuehne ICCV 2023 |
|
|
|
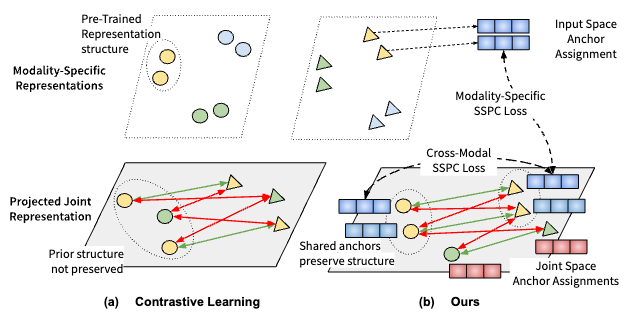
Preserving Modality Structure Improves Multi-Modal Learning
Sirnam Swetha, Mamshad Nayeem Rizve, Nina Shvetsova, Hilde Kuehne, Mubarak Shah ICCV 2023
|
|
|
|
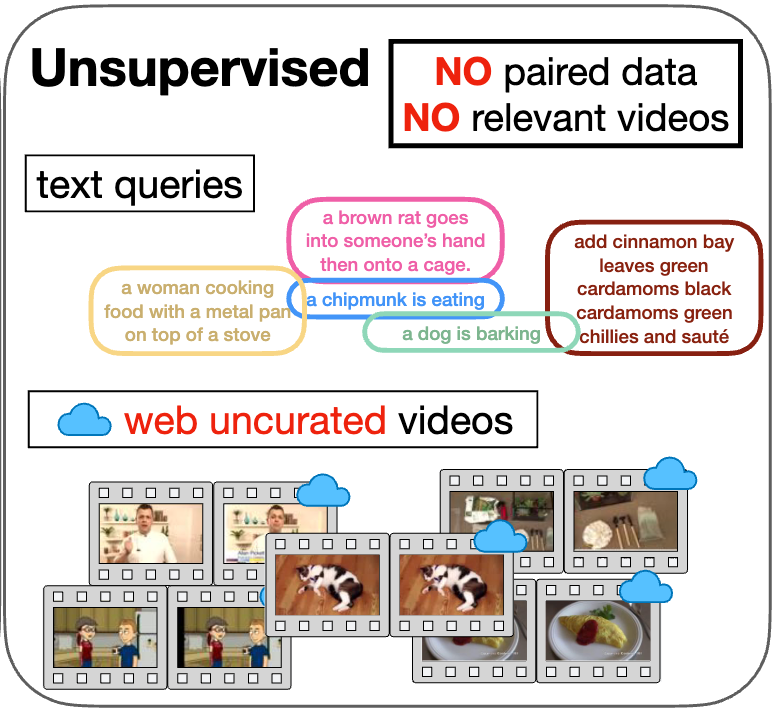
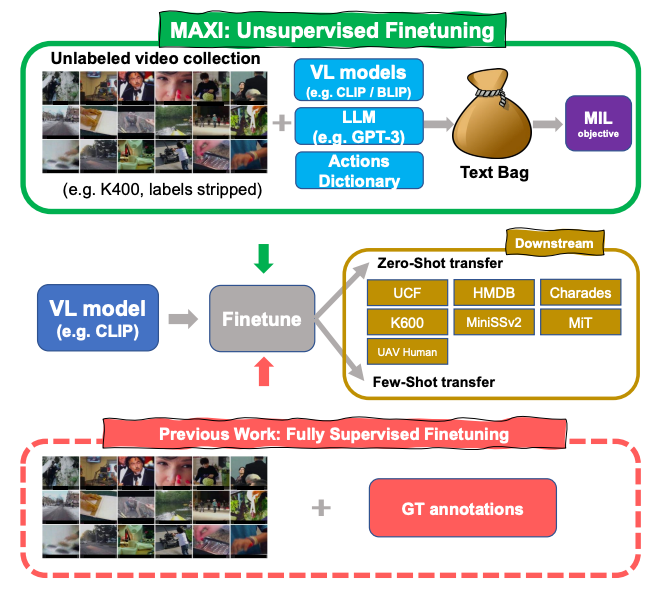
MAtch, eXpand and Improve: Unsupervised Finetuning for Zero-Shot Action Recognition with Language Knowledge
Wei Lin, Leonid Karlinsky, Nina Shvetsova, Horst Possegger, Mateusz Kozinski, Rameswar Panda, Rogerio Feris, Hilde Kuehne, Horst Bischof ICCV 2023 |
|
|
|
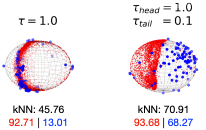
Learning by Sorting: Self-supervised Learning with Group Ordering Constraints
Nina Shvetsova, Felix Petersen, Anna Kukleva, Bernt Schiele, Hilde Kuehne ICCV 2023 |
|
|
|
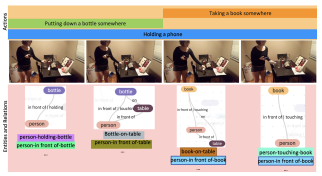
Learning Situation Hyper-Graphs for Video Question Answering
Aisha Urooj, Hilde Kuehne, Bo Wu, Kim Chheu, Walid Bousselham, Chuang Gan, Niels Lobo, Mubarak Shah CVPR 2023 |
|
|
|
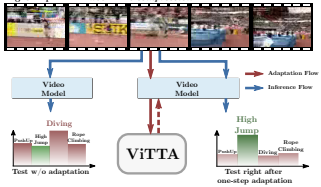
Video Test-Time Adaptation for Action Recognition
Wei Lin, Muhammad Jehanzeb Mirza, Mateusz Kozinski, Horst Possegger, Hilde Kuehne, Horst Bischof CVPR 2023 |
|
|
|
Temperature Schedules for self-supervised contrastive methods on long-tail data
Anna Kukleva, Moritz Boehle, Bernt Schiele, Hilde Kuehne, Christian Rupprecht arxiv 2022 |
|
|
|
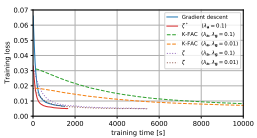
ISAAC Newton: Input-based Approximate Curvature for Newton's Method
Felix Petersen, Tobias Sutter, Christian Borgelt, Dongsung Huh, Hilde Kuehne, Yuekai Sun, Oliver Deussen ICLR 2023 |
|
|
|
Contrastive audio-visual masked autoencoder
Yuan Gong, Andrew Rouditchenko, Alexander H Liu, David Harwath, Leonid Karlinsky, Hilde Kuehne, James Glass ICLR 2023 |
|
|
|
Deep Differentiable Logic Gate Networks
Felix Petersen, Christian Borgelt, Hilde Kuehne, Oliver Deussen NeurIPS 2022 |
|
|
|
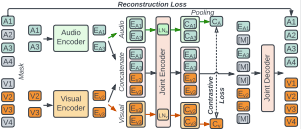
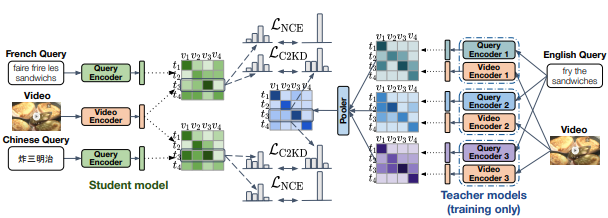
C2KD: Cross-Lingual Cross-Modal Knowledge Distillation for Multilingual Text-Video Retrieval
Andrew Rouditchenko, Yung-Sung Chuang, Nina Shvetsova, Samuel Thomas, Rogerio Feris, Brian Kingsbury, Leonid Karlinsky, David Harwath, Hilde Kuehne, James Glass arxiv 2022
|
|
|
|
VL-Taboo: An Analysis of Attribute-based Zero-shot Capabilities of Vision-Language Models
Felix Vogel, Nina Shvetsova, Leonid Karlinsky, Hilde Kuehne arxiv 2022
|
|
|
|
Differentiable top-k classification learning
Felix Petersen, Hilde Kuehne, Christian Borgelt, Oliver Deussen ICML 2022 |
|
|
|
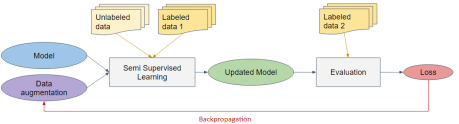
Augmentation Learning for Semi-Supervised Classification
Tim Frommknecht, Pedro Alves Zipf, Quanfu Fan, Nina Shvetsova, Hilde Kuehne GCPR 2022
|
|
|
|
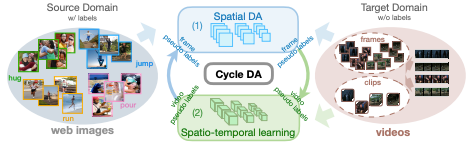
CycDA: Unsupervised Cycle Domain Adaptation to Learn from Image to Video
Wei Lin, Anna Kukleva, Kunyang Sun, Horst Possegger, Hilde Kuehne, Horst Bischof ECCV 2022
|
|
|
|
Weakly Supervised Grounding for VQA in Vision-Language Transformers
Aisha Urooj Khan, Hilde Kuehne, Chuang Gan, Niels Da Vitoria Lobo, Mubarak Shah ECCV 2022 (Oral) |
|
|
|
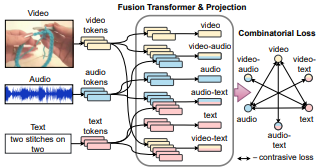
Everything at Once -- Multi-modal Fusion Transformer for Video Retrieval
Nina Shvetsova, Brian Chen, Andrew Rouditchenko, Samuel Thomas, Brian Kingsbury, Rogerio Feris, David Harwath, James Glass, Hilde Kuehne. CVPR 2022 |
|
|
|
Unsupervised Domain Generalization by Learning a Bridge Across Domains
Sivan Harary, Eli Schwartz, Assaf Arbelle, Peter Staar, Shady Abu-Hussein, Elad Amrani, Roei Herzig, Amit Alfassy, Raja Giryes, Hilde Kuehne, Dina Katabi, Kate Saenko, Rogerio Feris, Leonid Karlinsky. CVPR 2022 |
|
|
|
Monotonic Differentiable Sorting Networks
Felix Petersen, Christian Borgelt, Hilde Kuehne, Oliver Deussen. ICLR 2022 |
|
|
|
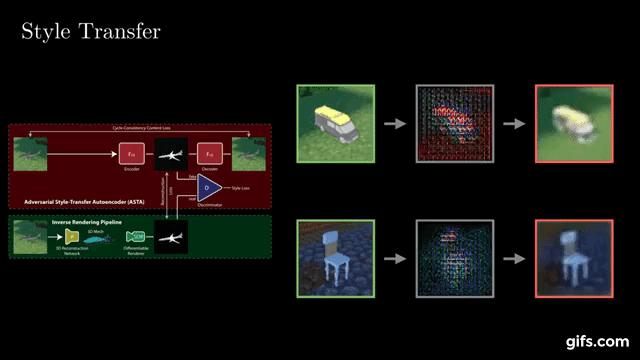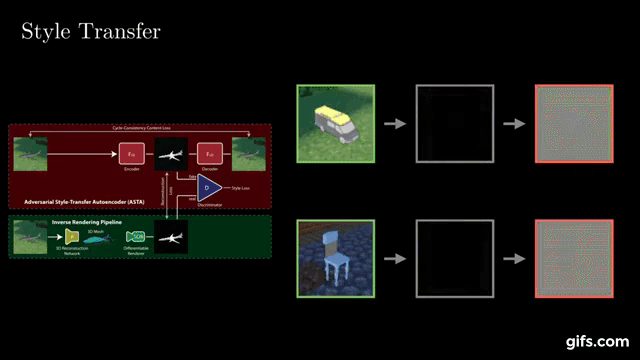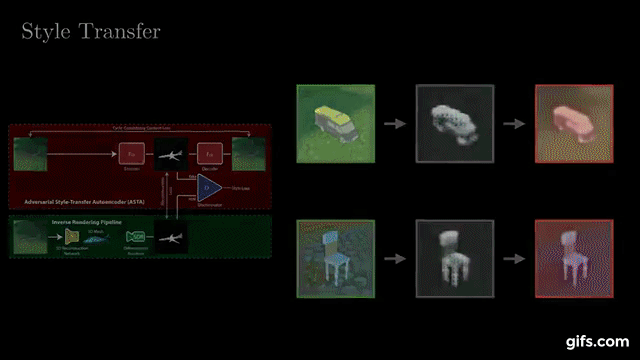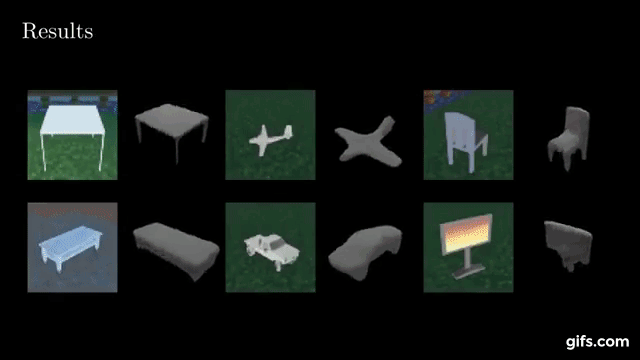
Style Agnostic 3D Reconstruction via Adversarial Style Transfer
Felix Petersen, Bastian Goldluecke, Oliver Deussen, Hilde Kuehne. WACV 2022 |
|
|
|
Learning with Algorithmic Supervision via Continuous Relaxations
Felix Petersen, Christian Borgelt, Hilde Kuehne, Oliver Deussen. NeurIPS 2021 |
|
|
|
Detector-Free Weakly Supervised Grounding by Separation
Assaf Arbelle, Sivan Doveh, Amit Alfassy, Joseph Shtok, Guy Lev, Eli Schwartz, Hilde Kuehne, Hila Barak Levi, Prasanna Sattigeri, Rameswar Panda, Chun-Fu Chen, Alex Bronstein, Kate Saenko, Shimon Ullman, Raja Giryes, Rogerio Feris, Leonid Karlinsky. ICCV 2021 (oral)
|
|
|
|
Multimodal Clustering Networks for Self-supervised Learning from Unlabeled Videos
Brian Chen, Andrew Rouditchenko, Kevin Duarte, Hilde Kuehne, Samuel Thomas, Angie Boggust, Rameswar Panda, Brian Kingsbury, Rogerio Feris, David Harwath, James Glass, Michael Picheny, Shih-Fu Chang. ICCV 2021 |
|
|
|
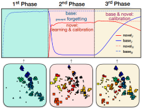
Generalized and Incremental Few-Shot Learning by Explicit Learning and Calibration without Forgetting
Anna Kukleva, Hilde Kuehne, Bernt Schiele. ICCV 2021
|
|
|
|
AVLnet: Learning Audio-Visual Language Representations from Instructional Videos
Andrew Rouditchenko, Angie Boggust, David Harwath, Brian Chen, Dhiraj Joshi, Samuel Thomas, Kartik Audhkhasi, Hilde Kuehne, Rameswar Panda, Rogerio Feris, Brian Kingsbury, Michael Picheny, Antonio Torralba, James Glass. Interspeech 2021
|
|
|
|
Cascaded Multilingual Audio-Visual Learning from Videos
Andrew Rouditchenko, Angie Boggust, David Harwath, Samuel Thomas, Hilde Kuehne, Brian Chen, Rameswar Panda, Rogerio Feris, Brian Kingsbury, Michael Picheny, James Glass. Interspeech 2021 |
|
|
|
Differentiable Sorting Networks for Scalable Sorting and Ranking Supervision
Felix Petersen, Christian Borgelt, Hilde Kuehne, Oliver Deussen. ICML 2021
|
|
|
|
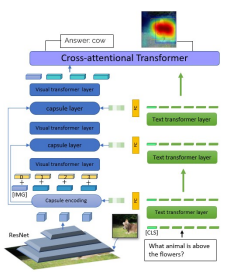
Found a Reason for me? Weakly-supervised Grounded Visual Question Answering using Capsules
Aisha Urooj Khan, Hilde Kuehne, Kevin Duarte, Chuang Gan, Niels Lobo, Mubarak Shah. CVPR 2021 |
|
|
|
Unsupervised Discriminative Embedding for Sub-Action Learning in Complex Activities
Sirnam Swetha, Hilde Kuehne, Yogesh S Rawat, Mubarak Shah. ICIP 2021
|
|
|
|
Joint visual-temporal embedding for unsupervised learning of actions in untrimmed sequences
Rosaura G VidalMata, Walter J Scheirer, Anna Kukleva, David Cox, Hilde Kuehne. WACV 2021
|
|
|
|
More Is Less: Learning Efficient Video Representations by Big-Little Network and Depthwise Temporal Aggregation
Quanfu Fan, Chun-Fu (Richard) Chen, Hilde Kuehne, Marco Pistoia, David Cox. NeurIPS 2019 |
|
|
|
Unsupervised learning of action classes with continuous temporal embedding
A. Kukleva*, H. Kuehne*, F. Sener, J. Gall. CVPR 2019 |
|
|
|
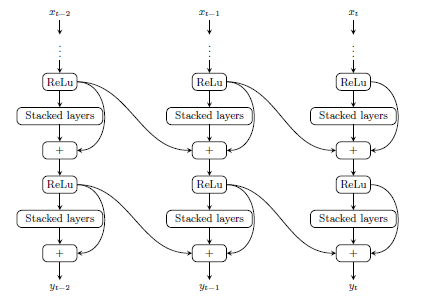
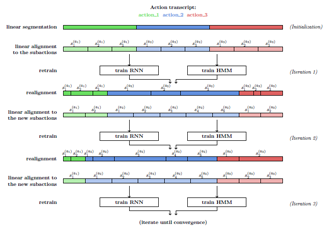
A Hybrid RNN-HMM Approach for Weakly Supervised Temporal Action Segmentation
Hilde Kuehne*, Alexander Richard*, Juergen Gall. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) 2019 (open access)
|
|
|
|
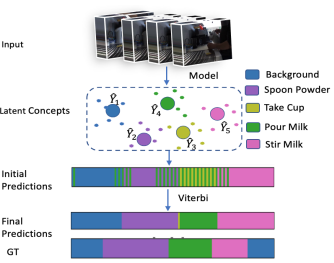
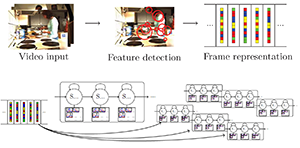
NeuralNetwork-Viterbi: A Framework for Weakly Supervised Video Learning
Alexander Richard, Hilde Kuehne, Ahsan Iqbal, Juergen Gall. CVPR 2018 |
|
|
|
Action Sets: Weakly Supervised Action Segmentation without Ordering Constraints
Alexander Richard, Hilde Kuehne, Juergen Gall. CVPR 2018 |
|
|
|
Recurrent Residual Learning for Action Recognition, German Conference on Pattern Recognition
Ahsan Iqbal, Alexander Richard, Hilde Kuehne, Juergen Gall. GCPR 2017 (Best Master's Award) |
|
|
|
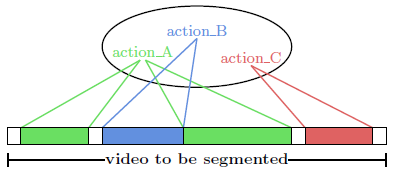
Weakly Supervised Action Learning with RNN based Fine-to-coarse Modeling |
|
|
|
Weakly supervised learning of actions from transcripts |
|
|
|
An end-to-end generative framework for video segmentation and recognition |
|
|
|
The Language of Actions: Recovering the Syntax and Semantics of Goal-Directed Human Activities |
|
|
|
On-line Action Recognition from sparse Feature Flow
|
|
|
|
HMDB: A Large Video Database for Human Motion Recognition |
|
Visapp
2010
|
|
Motion Segmentation of Articulated Structures by Integration of Visula Perception Criteria |
|
ICCV 2009,
|
|
An Iterative Scheme for Motion-Based Scene Segmentation
|